For instance

| Temperature (C) | Quad Occupancy |
| 0 | 0 |
| 3 | 0 |
| 5 | 0 |
| 6 | 1 |
| 7 | 0.5 |
| 9 | 2.3 |
| 10 | 5.1 |
| 12 | 6.7 |
| 13 | 6.1 |
| 15 | 8.6 |
Looking at the table on the left it is clear the Quad in occupied on average by more students at warmer temperatures but the shape of the relationship is hard to grasp just looking at the table. By plotting it as a scatter-plot ('visualizing') on the right it is clear no-one wants to be in the quad below 5 degrees then the number of students in the quad increases roughly linearly as the temperature increases and there is still no signs of the Quad getting full even once on average 8.6 students are sitting/working out there. Recently there is a fad for more and more fancy graphics to display larger and larger amounts of data at once. The problem with this is that increasingly data visualizations are more about the art and prettiness of the plot than about conveying information. Here are a few examples of modern data visualizations I've snatched from the internet:
Offender 1
 |
| Creator: Pehr Hovey, Source: http://pehrhovey.net/blog/2009/03/3d-data-visualization-dewey-calendar/ |
Offender 2
 |
| Source: GE Data Visualization http://visualization.geblogs.com/ |
Offender 3
 |
| Source: http://seeingcomplexity.wordpress.com/2011/03/13/why-visualize-data-we-dont-know-yet/ |
Another example of bad data visualization: some terms on the left and different countries/continents on the right, the area of the orange/brown arcs indicate population size. I don't know what the grey lines are supposed to represent (nor their colour/width) but it doesn't matter anyway since it is impossible to trace the path of almost all of the lines so impossible to know what is connected to what anyway. I guess I should give them some points for resisting the urge to unnecessarily use 3D graphics and at least having most of their labels be readable - except those ones at the bottom which are some of the few you can actually trace the links for. So yeah different places have different numbers of people (how much more or less is hard to tell since people are in general very bad at estimating areas) and are connected to different abstract concepts in different ways, feeling enlightened yet?
Offender 4
 |
| Source: http://blogs.uoregon.edu/teamingwithmicrobes/media/dataviz/ |
Another data visualization offender. Network visualizations are 90% of the time a complete waste of space because the only information they convey is "its fucking complicated". This network represents different bacterial species living in a corn seed (dots around the outside) and their co-occurrence in the same corn seed (lines). The colour of the line indicates whether they co-occur more (blue) or less (red) often than expected by chance. The size of the dot indicates how frequently the bacteria was found in corn seeds. We can get little information from this, common bacteria co-occur with many other species but not more often than expected (usually) while rare bacteria tend to co-occur more than expected (some of the time) with many other species, unfortunately the dots aren't labelled so we don't know which species these are nor does this arrangement of the network reveal whether the rare bacteria form multiple distinct groups which co-occur or whether they all are just out-competed by the common bacteria. Also because the figure is so messy it is hard to know if any of the patterns we see are statistically significant or the strength of those patterns (how much more likely are rare bacteria to co-occur more often than expected with other species than common bacteria?). Looking at this figure could help you form hypotheses which would be interesting to test but it doesn't reveal any answers or impart any knowledge in itself.
My Hero
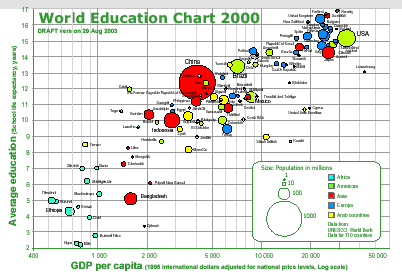 |
| Source: http://enthusiasm.cozy.org/archives/WorldEd.png |
Finally an example of effective data visualization. Notice the helpful axis labels explaining not only what the axis is but giving the units and values as well, the exquisite legend elucidating the meaning of the size and colour of each data point, the title saying what the graph is as well as the date the data is from. Unfortunately this low-resolution version I found makes the data labels hard to read but each country is represented and labelled. The trend is blissfully obvious (high education is associated with high GDP) without requiring you to squint or guess what is going on. Subpatterns and variability is easy to see as well - Africa is stuck down in the bottom-left while Europe is mostly in the top-right with the Americas, and Asia in between. Just as much data is represented here as in most of the other figures I've discussed (each country its population, GDP, education level) but the plot is much clearer and informative (and simpler to create) than the artistic but meaningless 3D images or the messy unreadable networks.